Коррупционная латиница: как орфография раскрыла коррупцию в Кыргызстане
Translations:
В 2013 году российский политический активист Алексей Навальный опубликовал в своем блоге статью под названием «Коррупционная латиница и как ее победить». В ней он описал коррупционную схему, используемую при госзакупках. Обычно государственный заказчик публикует объявление о покупке услуг или товаров — подрядчик с самой низкой ценой выигрывает тендер и поставляет товар/услуги. В случае же с коррупционной латиницей заказчик использует латинские буквы при размещении заказа (например, в слове «молоко» печатает латинскую «o»), и, таким образом, через поисковик сайта заказ найдёт только заранее осведомленный поставщик. Поставщик получит заказ по максимальной цене, а заказчику даст взятку.
Несколько лет назад в Кыргызской Республике было проведено расследование по коррупционной латинице. «На официальном сайте государственных закупок Кыргызстана меньше чем за год было скрыто минимум 72 тендера с использованием “коррупционной латиницы” на общую сумму 656 млн сомов (эквивалентно 9,6 млн долларов на июнь 2016 г.)», — пишет издание Акчабар.
В этой статье мы восстановим расследование и покажем, как выявить коррупционную латиницу с официального сайта госзакупок.
Пререквизиты:
Библиотеки — Вам понадобятся несколько библиотек Python. Для этого введите в командную строку cmd следующее:
pip install beautifulsoup4
pip install selenium
pip install pandas
selenium — для автоматизации действий веб-браузера; beautifulsoup4 — для извлечения данных с веб-сайта; pandas — для обработки и анализа данных.
Драйвер для браузера
https://www.seleniumhq.org/download/
По ссылке можно скачать драйвер для браузера, который вы предпочитаете (Chrome, Safari, Firefox и т. д.). После скачивания извлеките приложение в переменную среду PATH. Если не знаете как, то один из вариантов — написать в командую строку
path
Появятся локации на вашем компьютере, собственно, в одну из них и надо будет извлечь файл.
Кодим!
Создайте новый скрипт на Python под названием corruptlatin.py и напечатайте следующее.
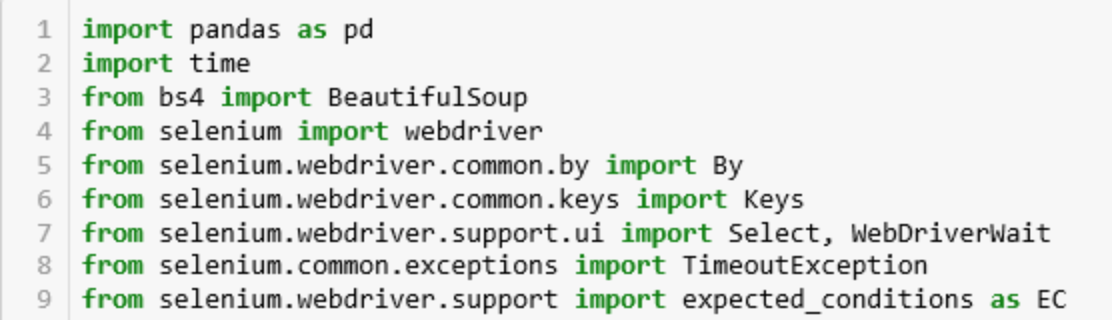
Как обычно, начинаем с загрузки модулей.

Эта команда открывает браузер. У меня Firefox, вы можете выбрать другой скачанный браузер. Соответственно, вместо Firefox печатаете Chrome, Safari и т. п.
Вторая же строка, как вы, наверное, угадали, открывает ссылку на сайт объявлений госзакупок.
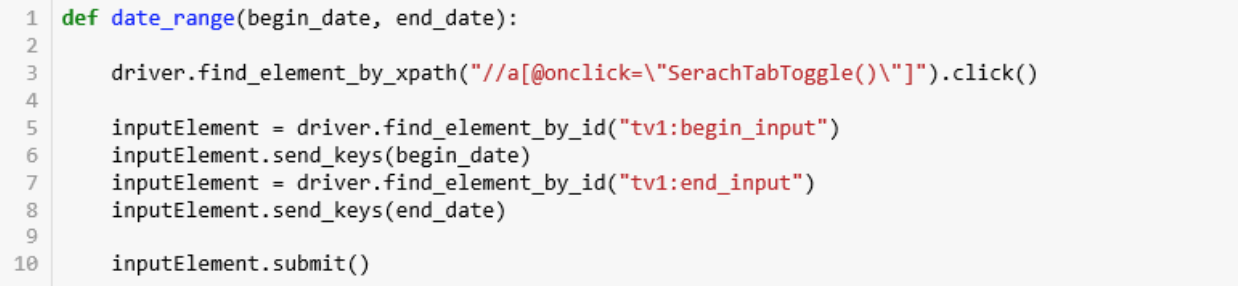
Создадим функцию, которая сузит количество объявлений по дате публикации:
- Строка 3. Браузер ищет кнопку «Расширенный поиск» по ее пути в HTML и нажимает на нее.
- Строки 5-8. В строки «Начало даты публикации» и «Окончание даты публикации» вводятся даты — параметры функции.
- Строка 10. Браузер утверждает запрос и выводит список объявлений, соответствующий запросу.
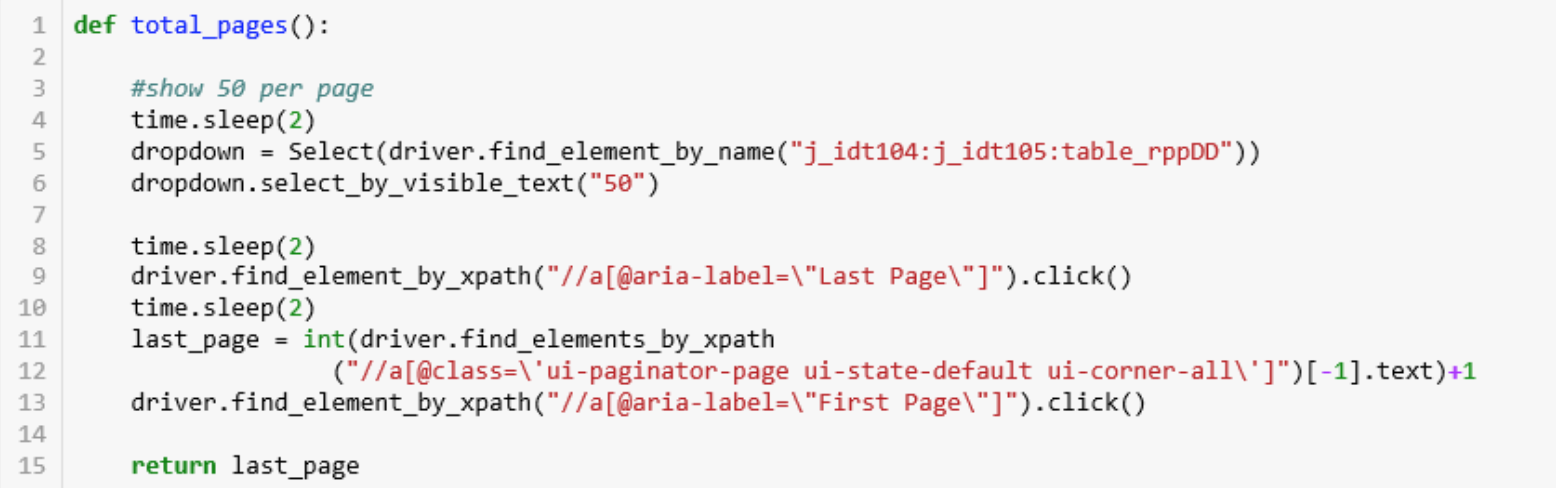
На этом сайте кнопка «Следующая страница» нажимается бесконечно. Поэтому важно определить количество страниц, чтобы на последней странице программа прекратила переходить на следующую страницу. Для этого нужно определить номер последней страницы. Создаем функцию без параметров, которая будет возвращать количество страниц.
- Строки 4-6: На сайте имеется прокрутка, которая определяет количество публикаций на странице. Чем больше публикаций на странице, тем меньше страниц, а то есть и времени для переключения на каждую. Поэтому надо выбрать максимальное количество и только потом определить количество страниц.
- Строка 4: Программа ничего не делает в течение 2 секунд. Это сделано для того, чтобы страница успела загрузиться.
- Строка 5. Найдя имя (также можно использовать id или путь) прокрутки в html, используем Select для нажатия.
- Строка 6: Выбираем максимальное количество — 50.
- Строка 9: Браузер нажимает на кнопку, ведущую на последнюю страницу
- Строка 11: На последней странице отображен номер страницы, но через html вытащить его не удалось. Однако на странице также есть номера предыдущих страниц. Пути html к ним все одинаковые, ищем их все, создается список, и выбираем последний, переводим в текст и далее в число. К числу добавляем один, и номер последней страницы известен.

- Строка 1: Вызываем функцию — определяем даты.
- Строки 2-3: Отображаем количество страниц и приблизительное время на их шерстку. На случай того, если выбранные даты требуют слишком много времени, можно будет их изменить.
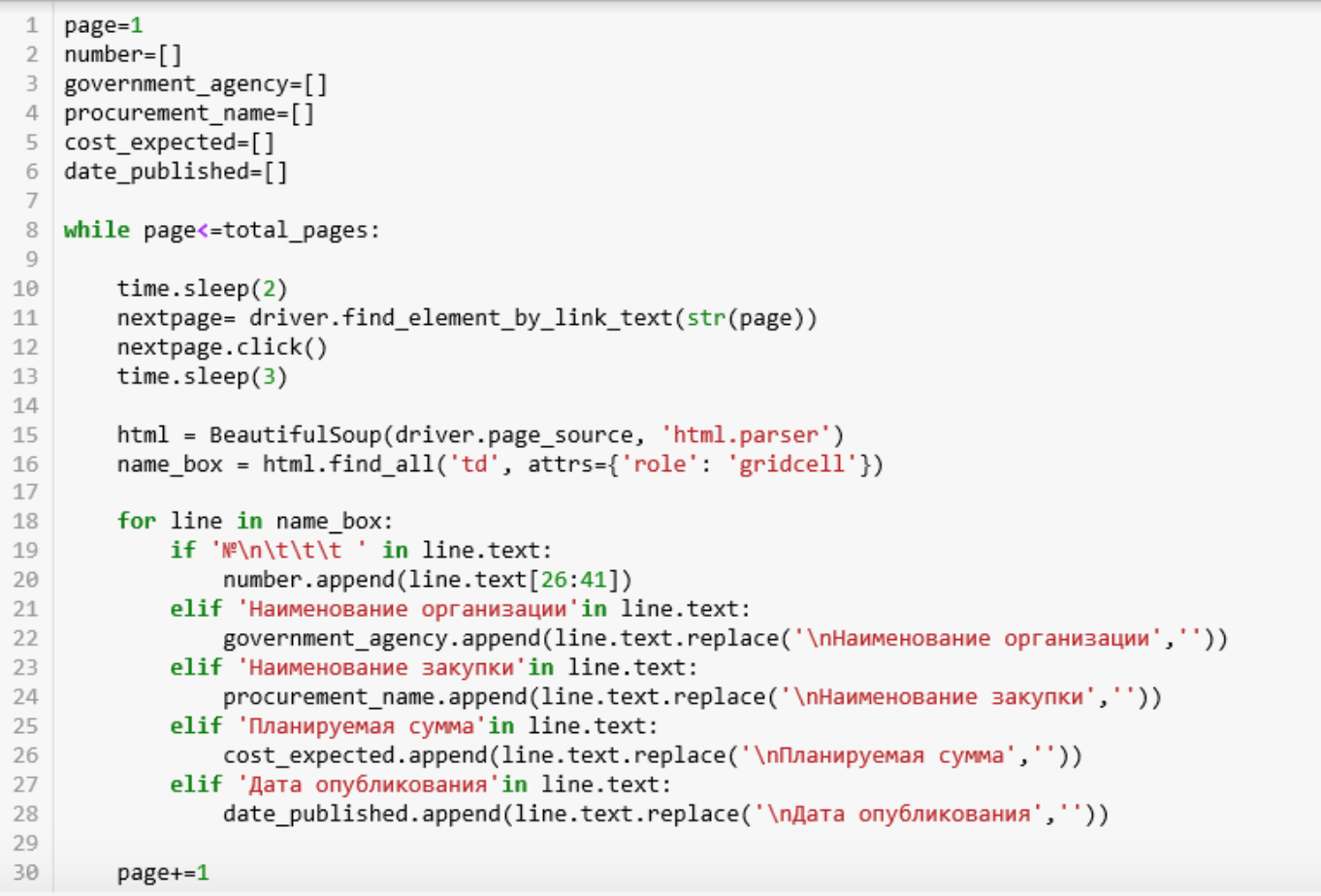
- Строки 1-6: Определяем переменные. Мы сейчас на первой странице; с каждой страницы мы будем вытаскивать информацию: номер, заказчик, заказ, ожидаемая цена, дата публикации — по этому списки
- Строка 8: Создаем луп, чтобы после шерстки браузер переходил на следующую страницу, пока не дойдет до последней. Иначе — бесконечность.
- Строки 11-12: Ищем страницу и нажимаем на нее. Первая — первая.
- Строка 13: Определяем время ожидания на 3 секунды, чтобы страница успела загрузиться перед тем, как начнется извлечение данных.
- Строки 15-16: Разбиваем html на понятный для питона текст и ищем, что нам надо. В данном случае это куски каждого объявления.
- Строки 18-28: Проходим по каждой строке, переводим в текстовый формат и сравниваем, есть ли в ней ключевые слова, которые определят, в какой список она попадет. По нахождении добавляем к определенному списку, заранее вычеркнув ненужные слова.
- Строка 30: Номер страницы увеличивается на один.

- Строки 31-33: Здесь все, думаю, ясно: соединяем листы и создаем базу данных.
- Строки 35-36: Проверяем, нет ли дублирующихся рядов, что может произойти, если страница не успела загрузиться, а данные начали извлекаться.
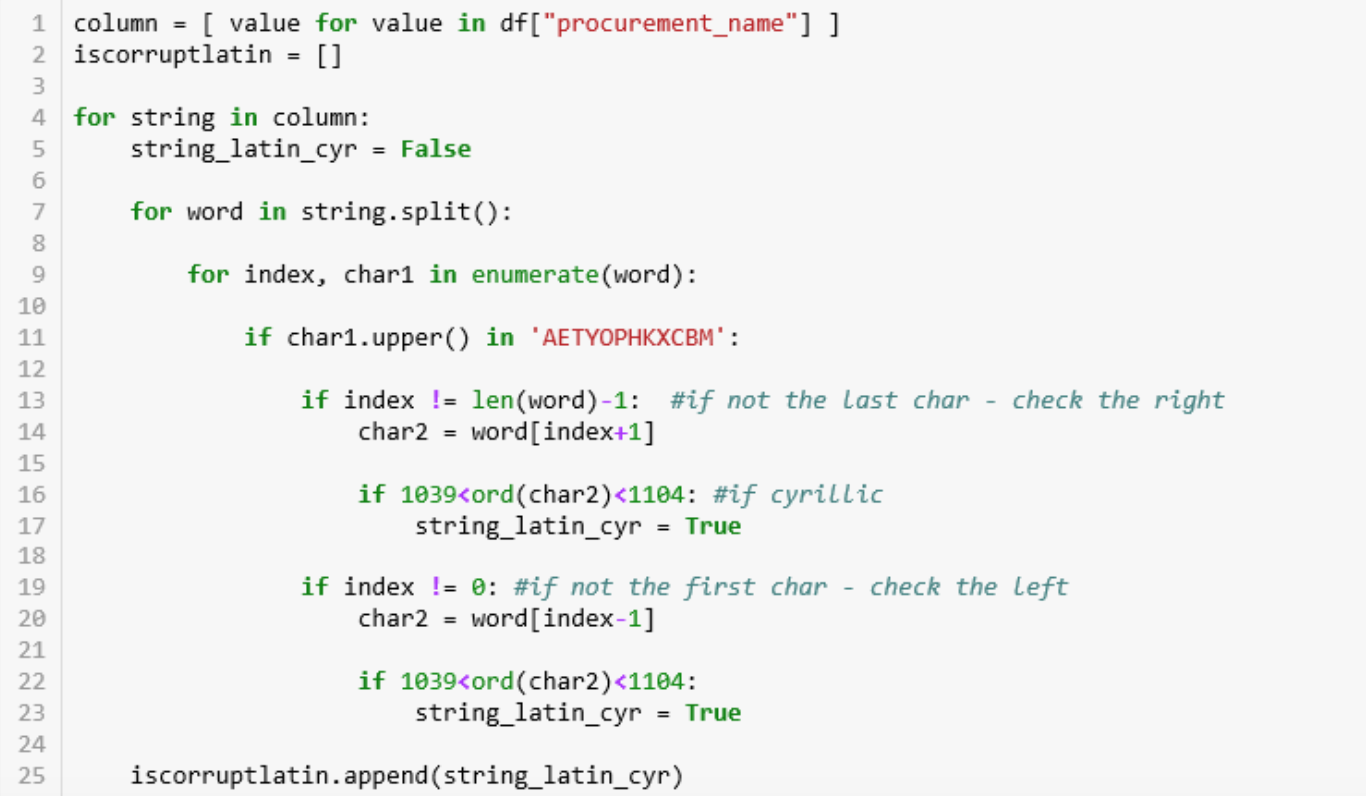
База данных готова, а значит, теперь можно искать в ней коррупционную латиницу! Просто искать латинские буквы не получится, так как в наименовании заказах встречаются английские слова (например название бренда Canon). Следовательно, ищем слова, содержащие как латиницу, так и кириллицу.
- Строки 1: Колонку, которая содержит название заказа, переделываем в список из серий, так легче шерстить по ней.
- Строки 4-9: В колонке заказов смотрим на каждый заказ (4). По умолчанию заказ не имеет коррупционной латиницы (5). Заказ разбиваем на слова (6) и потом и на символы, с индексом (7).
- Строки 11- 23: Если символ — латинская буква, похожая на кириллицу, то проверяем, являются ли символы справа (13) и слева (19) кириллицей, через личный номер каждого символа. Если кириллица, то — ТА-ДА! — мы нашли коррупционную латиницу (17, 23).
- Строка 25: прикрепляем нашу находку (или не находку) к списку.

- Строки 27-29: Наш список добавляем колонкой в базу данных, создаем новую, где исключительно встречается коррупционная латиница, и сохраняем в формате xlsx.
И всё!
Запускайте программу, наблюдайте, как ваш браузер сам открывает страницы и, наконец, узнайте, какие госорганы были замешаны в коррупционной латинице и на какую сумму.