
Как извлечь метаданные изображения при помощи Wayback Machine
Translations:
Эта статья была впервые опубликована в блоге AutomatingOSINT.com.
Не так давно я заинтересовался тайной сайта Oct282011.com. Еще не в курсе? Послушайте вот этот подкаст (на английском). Мы с моими друзьями – подписчиками Hunchly отправились в небольшое путешествие в надежде найти подсказку, ну и, конечно, разгадать эту загадку. Главным источником информации для нас стал Wayback Machine – популярный ресурс для ведения расследований.
На этот раз в качестве подсказок у нас была куча странных картинок, и я подумал, а не сможем ли мы извлечь эти фотографии из Wayback Machine и взглянуть на данные EXIF – может, там найдется информация об авторе или еще что-нибудь интересненькое? Конечно, заниматься этим вручную мне не хотелось. А значит, подумал я, вот она, прекрасная возможность придумать какой-нибудь инструмент, который сделает всю работу за меня.
Чтобы сотворить чудо, мы с вами воспользуемся двумя отличнейшими инструментами. Первый – это модуль в Python, который написал Джереми Сингер-Вайн, называется он waybackpack. Вообще, этот модуль можно использовать в командной строке как отдельный инструмент, но мы его просто импортируем, и его компоненты будут взаимодействовать с Wayback Machine. Второй инструмент – это ExifTool, разработанный Филом Харви. Эта волшебная штука – просто-таки эталон для извлечения данных EXIF из фотографий, надежное и проверенное средство, которым пользуются во всем мире.
Наша задача – взять все изображения для определенного URL-адреса в Wayback Machine, извлечь все данные EXIF и вывести всю информацию в список для удобного просмотра.
Итак, за дело!
Что нам понадобится
Задача перед нами стоит непростая, так что давайте сначала примемся за ее самую скучную и рутинную часть.
Установка Exiftool
Для дистрибутивов Linux, основанных на пакетной базе Ubuntu, можно сделать вот что:
# sudo apt-get install exiftool
Пользователи Mac OS X, скачайте программу-инсталлятор тут.
Если у вас стоит Windows, тогда:
- Скачайте двоичный фал ExifTool здесь. Сохраните его в папку C:\Python27 (у вас ведь уже стоит Python?)
- Переименуйте его в exiftool.exe
- Убедитесь, что в Path у вас указан путь к C:\Python27. Не знаете, как это сделать? Google вам в помощь. Или можете мне на электронную почту написать.
Установка необходимых библиотек Python
Теперь устанавливаем библиотеки Python, которые нам понадобятся:
pip install bs4 requests pandas pyexifinfo waybackpack
Ну что, поехали, ребята?
Пишем код
Открываем новый файл Python, называем его waybackimages.py (исходный код можно загрузить здесь) и вбиваем следующий код (не забывайте использовать обе руки):

Ну, тут пока ничего особенного. Мы просто импортируем все нужные модули, задаем целевой URL-адрес и создаем папку, где будут храниться все изображения.
Теперь создадим первую функцию, которая будет запрашивать у Wayback Machine все уникальные фотографии нашего целевого URL-адреса:
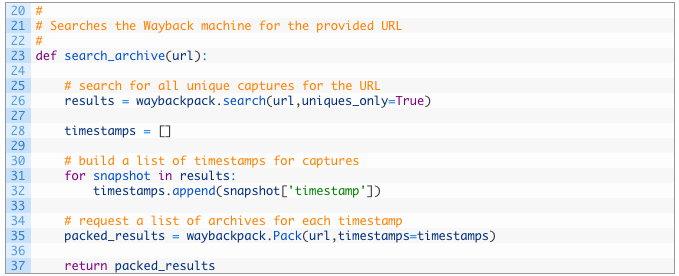
- Строка 24: функция search_archive принимает аргумент url – это URL-адрес, который мы будем искать в сервисе Wayback Machine.
- Строка 27: используем функцию search, предоставленную waybackpack, для поиска нашего URL-адреса, а также указываем, что нас интересуют только уникальные фотографии, иначе нам придется просматривать кучу повторяющихся.
- Строки 29-33: создаем пустой список временных меток (29), начинаем проходить результаты поиска (32) и добавлять временные метки, соответствующие определенным снимкам в Wayback Machine (33).
- Строки 36-38: указываем оригинальный URL и список временных меток для создания объекта Pack (36). Объект Pack собирает временные метки и URL-адреса в формате, совместимом с Wayback Machine. Возвращаем объект функции (38).
Итак, функция поиска у нас реализована, теперь нам нужно обработать результаты, извлечь все зафиксированные страницы, а потом извлечь все пути к изображениям, хранящимся в HTML. Этим мы сейчас и займемся.

- Строка 43: функция get_image_paths принимает объект Pack.
- Строки 48-56: проходим список ресурсов (48), применяем функцию get_archive_url (51), чтобы получить пригодный для использования URL. Выводим небольшую подсказку (53), извлекаем HTML при помощи функции fetch (56).
- Строки 59-60: теперь у нас есть HTML, мы передаем его в BeautifulSoup (59) и начинаем разбирать HTML, чтобы получить теги изображений. Для разбора мы используем функцию findAll (60), которой присваиваем аргумент img. В итоге мы получаем список тегов IMG, найденных в HTML.
- Строки 63-70: проходим список найденных тегов IMG (64), создаем URL-адреса (67-70) изображений, при помощи которых позже можно будет извлечь сами изображения.
- Строки 72-74: если URL-адреса еще нет в списке (72), выводим сообщение (73) и добавляем URL изображения в список всех найденных фотографий (74).
Отлично! Мы извлекли все URL-адреса изображений, теперь их нужно загрузить и обработать, чтобы получить данные EXIF. Этим мы сейчас и займемся.
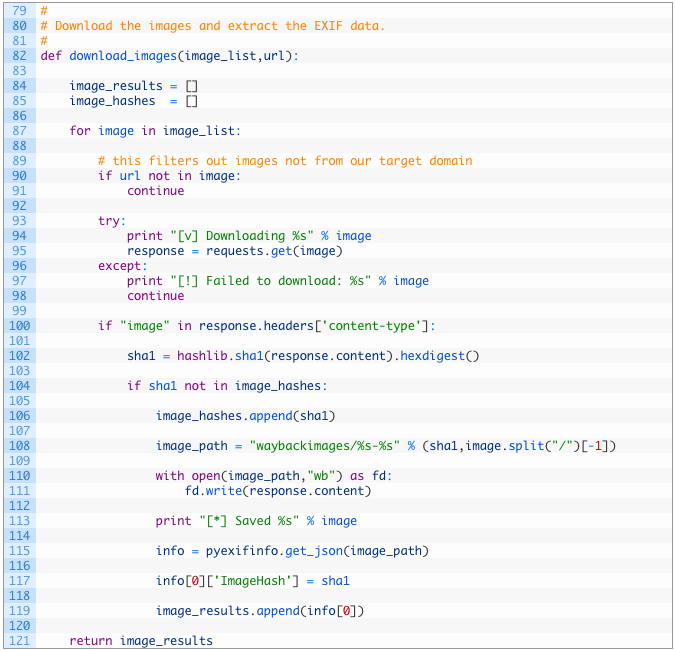
Давайте разберем этот участок кода поподробнее:
- Строка 83: в качестве аргумента для функции download_images задаем наш большой список URL-адресов изображений и оригинальный URL-адрес.
- Строки 85-86: создаем переменную image_results (85), которая будет содержать все результаты по данным EXIF, и переменную image_hashes (86), которая будет следить за всеми уникальными хешами загружаемых изображений. Это если вкратце.
- Строки 88-98: проходим список URL-адресов изображений (88), если базовый URL не указан в пути к изображению (91), игнорируем его. Затем загружаем изображение (96), чтобы проанализировать.
- Строки 101-103: если изображение загружено (101), применяем к изображению хеш-алгоритм SHA-1, чтобы отследить уникальные изображения. Если у нас есть несколько изображений с одинаковым именем файла, а их содержание при этом различается (хотя бы на один бит), то мы будем рассматривать их отдельно. Кроме того, это поможет нам избавиться от повторяющихся изображений.
- Строки 105-114: если изображение является новым и уникальным (105), его хеш добавляется в список хешей изображений (107), а само изображение записывается на диск (111).
- Строка 116: вызываем get_json, функцию pyexifinfo. Эта функция извлекает данные EXIF и возвращает результат в виде словаря Python.
- Строки 118-120: добавляем в словарь info собственный ключ, который содержит хеш SHA-1 изображения (118), вносим словарь в главный список результатов (120).
Ну что же, мы почти закончили. Осталось только связать все эти функции и вывести результат в формате CSV для удобного просмотра извлеченных данных EXIF. Вот они, завершающие штрихи нашего скрипта.
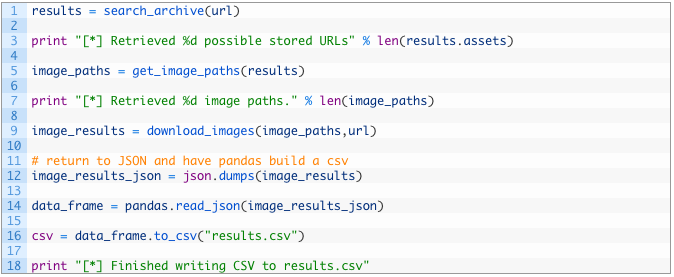
Это последний участок кода, давайте разберем его поподробнее:
- Строки 124-132: вызываем все функции, начиная выполнять поиск в Wayback Machine (124), извлекая пути к изображениям (128), загружая и анализируя все изображения (132).
- Строки 135-139: конвертируем полученный словарь в строку JSON (135), подставляем ее в read_json, функцию pandas (137), чтобы создать кадр данных в pandas. Затем используем замечательную функцию to_csv, которая конвертирует этот кадр данных в файл CSV с автоматическим созданием колонок с заголовками. Теперь нам не надо писать сложный код, чтобы создать файл CSV. Файл CSV хранится в results.csv, там же, где и скрипт.
Погнали!
Наконец-то пришла пора повеселиться. Выберите какой-нибудь URL, который вас интересует, и запустите скрипт из командной строки или своей любимой IDE для Python. Результат должен получиться примерно таким:
[*] Retrieved 41 possible stored URLs
[*] Retrieving https://web.archive.org/web/20110823161411/http://www.oct282011.com/ (1 of 41)
[*] Retrieving https://web.archive.org/web/20110830211214/http://www.oct282011.com/ (2 of 41)
[+] Adding new image: https://web.archive.org/web/20110830211214/http://www.oct282011.com/st.jpg
…
[*] Saved https://web.archive.org/web/20111016032412/http://www.oct282011.com/material_same_habits.png
[v] Downloading https://web.archive.org/web/20111018162204/http://www.oct282011.com/ignoring.png
[v] Downloading https://web.archive.org/web/20111018162204/http://www.oct282011.com/material_same_habits.png
[v] Downloading https://web.archive.org/web/20111023153511/http://www.oct282011.com/ignoring.png
[v] Downloading https://web.archive.org/web/20111023153511/http://www.oct282011.com/material_same_habits.png
[v] Downloading https://web.archive.org/web/20111024101059/http://www.oct282011.com/ignoring.png
[v] Downloading https://web.archive.org/web/20111024101059/http://www.oct282011.com/material_same_habits.png
[*] Finished writing CSV to results.csv